Acuity.ai
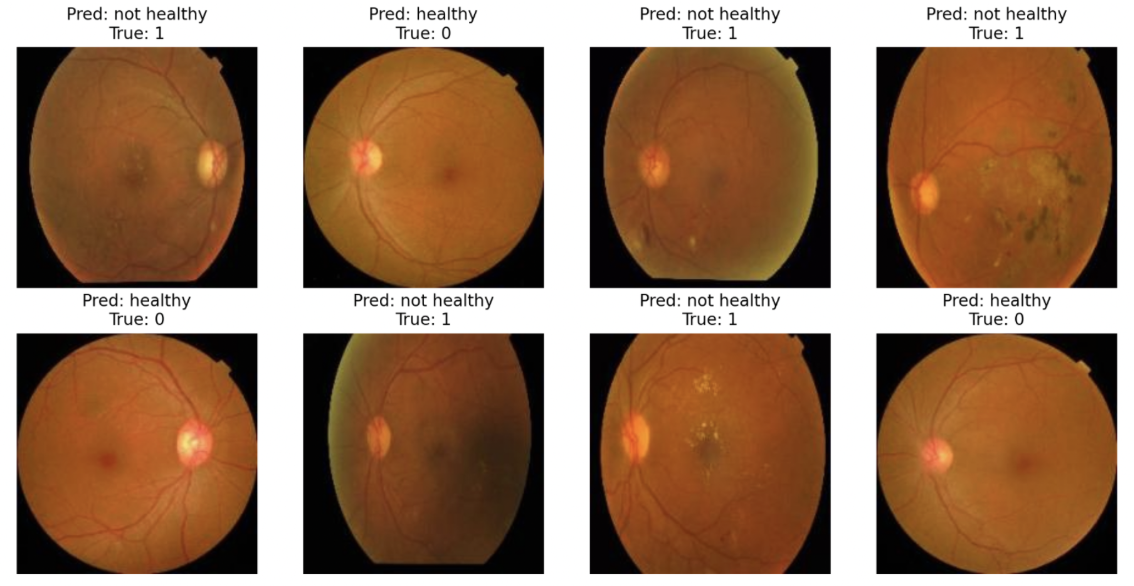
- Developed an AI clinical assistant which helps assess a patient's risk of readmission to the Emergency Department.
- Leveraged regex-based NLP to parse medical documents and ensemble modeling generate accurate predictions.
- Architected a RAG pipeline to surface relevant medical knowledge for chatbot responses
- Deployed using FastAPI to manage patient data, predictions and chatbot states